1. 了解語音合成過程
目前語音合成
--用LPC model vocal tract
--程式中的model vocal tract部分希望改成sine
2. 如何用HMM輔助合成
showmin的合成
--音色庫先建好
--LPC+sine是用來Model Harmonics
--HMM只是來輔助合成的
3. 目標
了解語音合成的程式碼,
將showmin之LPC model sine的方法修改或套用至語音合成,
再用HMM輔助合成,並整合到authingtool.
希望能用CUDA加速.
2010年5月19日 星期三
HMM matlab example
=======產生hmm sequence========
1. 定義transition probability和 emis probability .
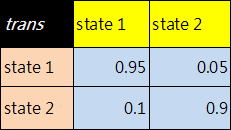
trans = [0.95,0.05 ;
0.10,0.90 ] ;
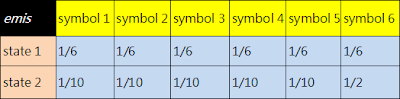
emis = [1/6 1/6 1/6 1/6 1/6 1/6;
1/10 1/10 1/10 1/10 1/10 1/2 ];
2. 用定義好的probability隨機產生一個sequence.
seq 存的是在第 i 步時的symbol,
states 存的是在第 i 步時所在的 state.
[seq,states] = hmmgenerate( 8,trans,emis);
result :

3. 可對symbols 及 states 另取名稱 .
[seq,states] = hmmgenerate( 8 ,trans,emis,...
'Symbols',{'one','two','three','four','five','six'},...
'Statenames',{'fair';'loaded'})
result :

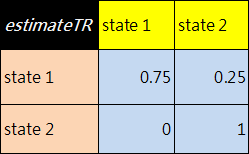
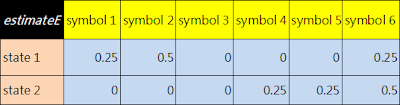
==用已知的sequence, states反推出 trans 和 emis 機率==
1. 用此matlab指令
[estimateTR,estimateE] = hmmestimate(seq,states);
result :
=======pStates========
trans, emis, seq同上,輸入matlab指令.
PSTATES = hmmdecode(seq,TRANS,EMIS);
result :

1. 定義transition probability和 emis probability .
trans = [0.95,0.05 ;
0.10,0.90 ] ;

emis = [1/6 1/6 1/6 1/6 1/6 1/6;
1/10 1/10 1/10 1/10 1/10 1/2 ];
2. 用定義好的probability隨機產生一個sequence.
seq 存的是在第 i 步時的symbol,
states 存的是在第 i 步時所在的 state.
[seq,states] = hmmgenerate( 8,trans,emis);
result :

3. 可對symbols 及 states 另取名稱 .
[seq,states] = hmmgenerate( 8 ,trans,emis,...
'Symbols',{'one','two','three','four','five','six'},...
'Statenames',{'fair';'loaded'})
result :

==用已知的sequence, states反推出 trans 和 emis 機率==
1. 用此matlab指令
[estimateTR,estimateE] = hmmestimate(seq,states);
result :


=======pStates========
trans, emis, seq同上,輸入matlab指令.
PSTATES = hmmdecode(seq,TRANS,EMIS);
result :

Hidden Markov Models with matlab

PSTATES = hmmdecode( o_seq, TRANS, EMIS):給定observed sequence, 用來計算conditional probabilities在state k at step i .
TRANS( i, j ):由 state i 至 state j 的轉換機率 .
EMIS( k, sym_seq ):symbol sequence 在 state k 發生的機率.
PSTATES:是個矩陣跟 seq 的大小一樣, 第 ( i, j )th element 代表在model中 state i at jth step 的機率 .
[ PSTATES, logpseq ] = hmmdecode(...):回傳對數的 probability sequence, logseq .
[ PSTATES, logpseq, FORWARD, BACKWARD,S ] = hmmdecode(...):給定 scaled s, 回傳 forward 和 backward 的 sequence 機率 .
hmmdecode( o_seq, TRANS, EMIS ,'Symbols', SYMBOLS):定義有哪些 SYMBOLS , SYMBOLS可為陣列 .
=========================================

[seq,states] = hmmgenerate(len,TRANS,EMIS):用已知的transition probability TRANS, 與 symbol probability EMIS 並指定欲產生 sequence 的長度, 來造出一個 observed sequence with states .
hmmgenerate(...,'Symbols',SYMBOLS):定義有哪些 SYMBOLS , SYMBOLS可為陣列 .
hmmgenerate(...,'Statenames',STATENAMES):定義 states 的名稱 .
=========================================

[TRANS,EMIS] = hmmestimate( seq, states ):給定 sequence 和 states 算出 TRANS, EMIS 的maximum likelihood estimate .
hmmestimate(...,'Symbols',SYMBOLS):定義有哪些 SYMBOLS , SYMBOLS可為陣列 .
hmmestimate(...,'Statenames',STATENAMES):定義 states 的名稱 .
hmmestimate(...,'Pseudoemissions',PSEUDOE):用此參數來避免state內無symbol的機率, PSEUDOE 是個矩陣 size m-by-n , m為states數目, n為該state可能產生的symbol數.
如果在sequence中state i at k step的機率為0, 可設 PSEUDOE( i, k ) 指定在 state i at k step的機率 .
hmmestimate(...,'Pseudotransitions',PSEUDOTR):用此參數來避免state與state間的0轉換機率, PSEUDOTR 是個矩陣 size m-by-m , m為states數目 .
如果在sequence中從state i 至 state k 的機率為0, 可設 PSEUDOTR( i, j ) 指定從state i 至 state k 的機率 .
=========================================

STATES = hmmviterbi(seq,TRANS,EMIS):給定model參數TRANS, EMIS 和 observed sequence, 計算 most likely path.
=========================================

[ESTTR,ESTEMIT] = hmmtrain(seq,TRGUESS,EMITGUESS):用Baum-Welch algorithm估計transition和state emission probabilities. TRGUESS, EMITGUESS為我們猜測的transition 和 symbol probabilities matrix.
註: state emission probability為一個state可能產生的output狀態, 即為一個state所擁有的symbol數.
hmmtrain(...,'Algorithm',algorithm):定義要用哪種演算法來training data. 有 BaumWelch 和 Viterbi 兩種, 預設是 BaumWelch .
hmmtrain(...,'Tolerance',tol):定義容忍度,預設值為0.0001, 用來在估計過程中測試收斂.
hmmtrain(...,'Maxiterations',maxiter):定義在estimation過程中最大可以 iterate 的數目, 預設為 100.
hmmtrain(...,'Verbose',true):回傳status of algorithm at each iteration.
如果已知states與sequences的關係, 就用hmmestimate去估計 model 的參數.
訂閱:
文章 (Atom)